


Oct 20, 2022
Work during my research internship at Audio Information Research Lab with You (Neil) Zhang, and Professor Zhiyao Duan.
Abstract
Voice anti-spoofing systems are crucial auxiliaries for automatic speaker verification (ASV) systems. A major challenge is caused by unseen attacks empowered by advanced speech synthesis technologies. Our previous research on one-class learning has improved the generalization ability to unseen attacks by compacting the bona fide speech in the embedding space. However, such compactness lacks consideration of the diversity of speakers. In this work, we propose speaker attractor multi-center one-class learning (SAMO), which clusters bona fide speech around a number of speaker attractors and pushes away spoofing attacks from all the attractors in a high-dimensional embedding space. For training, we propose an algorithm for the co-optimization of bona fide speech clustering and bona fide/spoof classification. For inference, we propose strategies to enable anti-spoofing for speakers without enrollment. Our proposed system outperforms existing state-of-the-art single systems with a relative improvement of 38% on equal error rate (EER) on the ASVspoof2019 LA evaluation set.
Method
Multiple bona-fide clusters within one-class learning framework to conduct binary classification: real human speech VS. synthesized speech attacks.




Results
Baseline Comparison


Ablation Studies


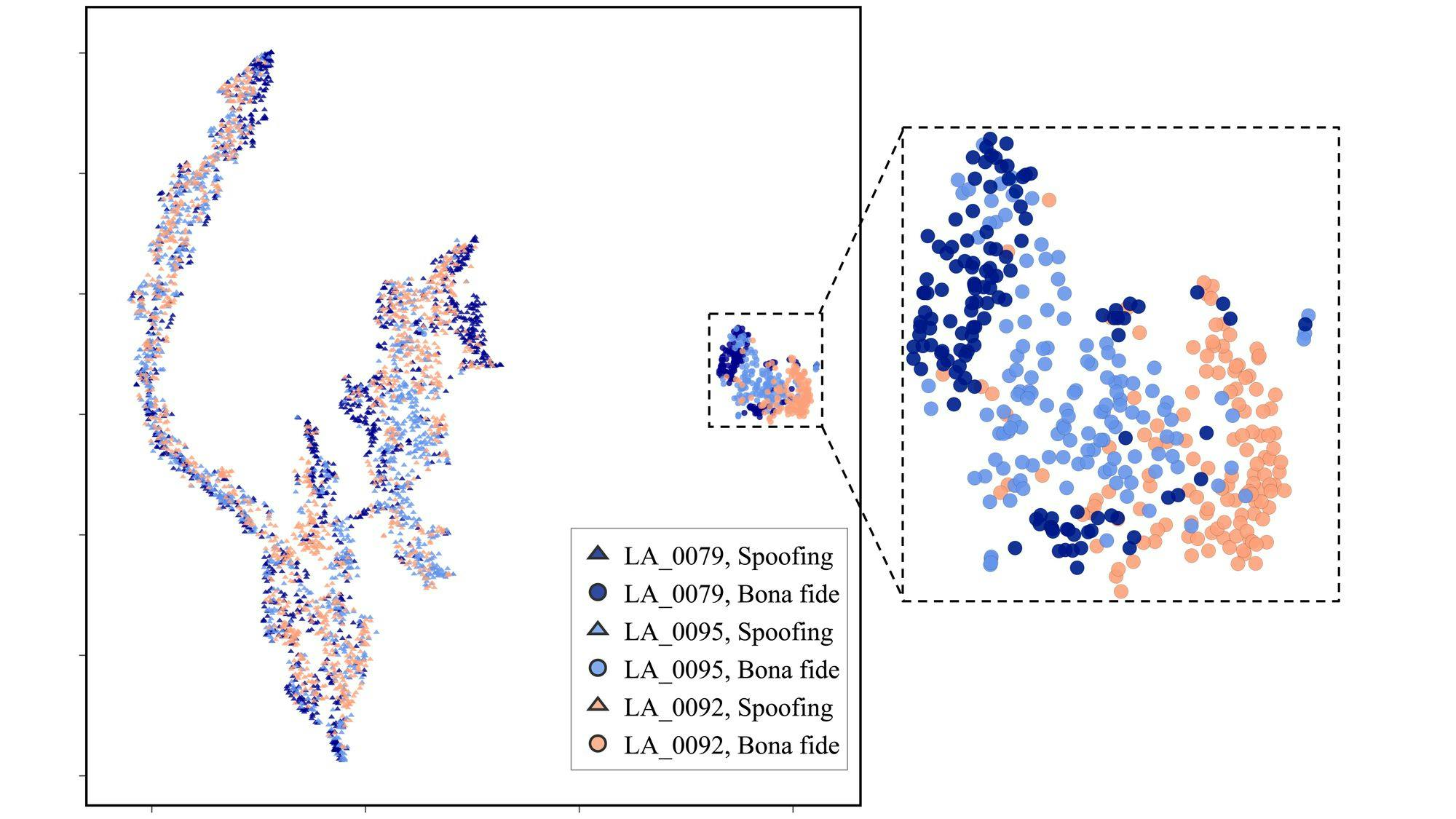
Visualization (t-SNE)


Paper (Submitted to ICASSP 2023)


Codes


Citation
@article{ding2022samo, title={SAMO: Speaker Attractor Multi-Center One-Class Learning for Voice Anti-Spoofing}, author={Ding, Siwen and Zhang, You and Duan, Zhiyao}, journal={arXiv preprint arXiv:2211.02718}, year={2022} }
References
@ARTICLE{zhang21one, author={Zhang, You and Jiang, Fei and Duan, Zhiyao}, journal={IEEE Signal Processing Letters}, title={One-Class Learning Towards Synthetic Voice Spoofing Detection}, year={2021}, volume={28}, number={}, pages={937-941}, doi={10.1109/LSP.2021.3076358}} @article{wang2020asvspoof, title={ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech}, author={Wang, Xin and Yamagishi, Junichi and Todisco, Massimiliano and Delgado, H{\'e}ctor and Nautsch, Andreas and Evans, Nicholas and Sahidullah, Md and Vestman, Ville and Kinnunen, Tomi and Lee, Kong Aik and others}, journal={Computer Speech \& Language}, volume={64}, pages={101114}, year={2020}, publisher={Elsevier} } @INPROCEEDINGS{Jung2021AASIST, author={Jung, Jee-weon and Heo, Hee-Soo and Tak, Hemlata and Shim, Hye-jin and Chung, Joon Son and Lee, Bong-Jin and Yu, Ha-Jin and Evans, Nicholas}, booktitle={arXiv preprint arXiv:2110.01200}, title={AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks}, year={2021}